
1. Background
If experimentation is a third wheel, then, naturally, most companies would look to buy a ready-made solution. It is a common business strategy to avoid building a product that is extramural to company’s core expertise. For the reasons that are the subject of this article, buying instead of building an experimentation infrastructure hasn’t worked any better than the other way around. At least not as well as what the investors had in mind when they handed Dan Siroker and Pete Koopman, the founders of Optimizely, their seed round in 2010.
To understand why, I need to rewind to the early aughts, when the web was being first embraced by traditional businesses. Back then, the word “Web” was capitalized, there were exactly two browsers—Netscape and Internet Explorer,—and a web application looked like this:

2. Motivation
The early demand for online experiments came from two distinct directions. Tech-centric companies embraced the practice as a necessary part of product development, where product ideas are regarded as inherently falsifiable, and subject to empirical verification. Search engines, for example, had to conduct relentless A/B tests to tune their algorithm.
The other motivation for experimentation was marketing. Systematically trained marketers had known the power of A/B testing way before the internet. Typically, these marketing experiments tested not the new product features, but the ways to improve user experience around existing features. Even though most of these adjustments would be made to the client-side, the server had to be involved in sending the right variant of the HTML page to the browser. Successful brands understood the value of UI optimization and began building A/B testing infrastructure into their backends early on. But most others lacked the foresight or the aptitude, leaving their customers with subpar user experience and their marketing departments with the budget, but not the leverage to put A/B testing on the product roadmap.
3. Before 2009
It is this budget that paid for Eric Hansen’s lunch, when in 2003 he founded SiteSpect, the first company targeting UI optimization. His technology acted as a network proxy between the customer’s server and the internet, responsible for re-writing the server’s generic response into one of the test variants and routing it to the right user agent.
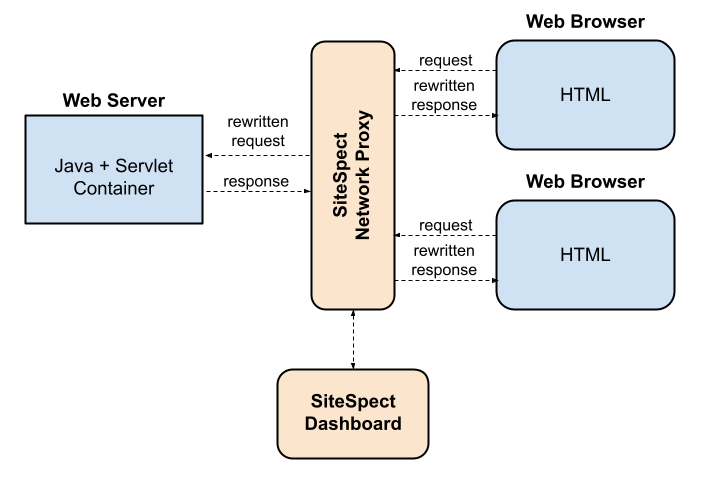
If there’s anything to be learned from this feat of business acumen, it is that an additional layer of indirection can not only solve any problem in computer science, but also some in organizational complexity. Although a different company now than it was then, SiteSpect’s early customer roster was—and mostly remains—a list of brands who openly admitted to such a degree of organizational dysfunction, that the CTO would rather surrender his site’s A-record than take responsibility for experimentation. One doesn’t need much imagination to conjure up a horror story involving a web app fronted by brittle, GUI-defined re-writing rules cobbled together outside proper product development organization and not subject to regular release schedule and testing. I summarize the pros and cons of SiteSpect’s original tech as follows:
| Pros | Cons |
| • Enables non-technical staff to conduct shallow experiments without needing to talk to engineers. • No server-side code is required. • Low, predictable response time overhead. | • Brittle and error prone. No programmatic capabilities beyond regular expression substitutions. • Requires vendor professional services to instrument.• Remediation of production incidents is organizationally complicated. • Static, pre-defined targeting. • Only shallow experiments are supported. Not possible to use targeting capabilities to conduct server-side experiments1. |
4. After 2009
Before 2009, if your goal was to not roll your own A/B testing, SiteSpect was the only game in town. Then, in a short succession, several new companies came along with a novel technique of instrumenting shallow A/B tests enabled by a groundbreaking new technology. In March of 2009 Microsoft released AJAX on its Internet Explorer 5 browser, and later that year JavaScript 5 was released with its native support for JSON. Now, it was possible to manipulate the content of a web page programmatically based on some external configuration which could be retrieved from the cloud in real time.
From then on, every new entrant in what was to become a very busy field of A/B testing SaaS, implemented client-side instrumentation model, where HTTP traffic was proxied through a JavaScript library which made asynchronous calls to the vendor’s runtime to find out what version of the page to show and re-rendered the page accordingly.
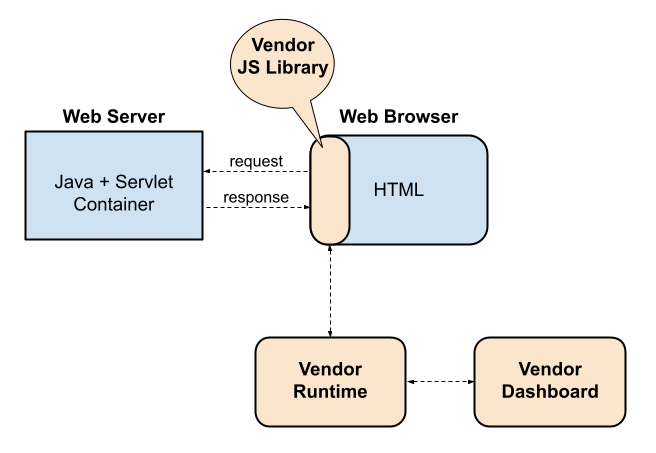
Compared with Figure 2, the new architecture was an obvious improvement. The CTO only had to put a reasonably dependable vendor JavaScript library onto every page, and a marketer could then design sophisticated shallow experiments entirely in the vendor’s graphical dashboard using standard browser-based toolchain.
Nonetheless, these new improvements did not come without a cost. The instrumentation overhead was now dependent on the power of the user’s computer and her network bandwidth. This frequently resulted in complaints of page flickering and slow TTI due to the experimentation, which have been well documented. I summarize the pros and cons of the early SaaS architecture as follows:
| Pros | Cons |
| • Enables non-technical staff to conduct shallow experiments without needing to talk to engineers. No server-side code is required. • Improved velocity and reliability of A/B tests. | • Unpredictable and often unacceptable response time overhead. • Static, pre-defined targeting. • Only shallow experiments are supported. • Not possible to use targeting capabilities to conduct server-side experiments. |
5. The Limits of SaaS
That after roughly $500M venture investment (half of it into Optimizely), none of the A/B testing startups founded between ’09 and ’15 presently stand a chance to grow to a size expected by these investments is a clear sign that something didn’t work out as planned. In my view, it is the failure to penetrate the enterprise market. A long held maxim in the software business is that there’s no real business in the SNB market alone. The amount of VC investment suggests to me that the TAM was estimated in billions, but turned out an order of magnitude less, and for a simple reason: enterprise customers need to run complex experiments involving both the client and the server. Shallow experimentation alone doesn’t move the needle for the enterprise customer.
This limitation must have became obvious right around ’15 when Optimizely raised more cash to build a “full-stack” solution, dubbed “Optimizely X,” which it released the next year. Other competitors too quickly offered an architecturally similar solution. It was a simple-minded extension of the existing tech with a server-side SDK, communicating with the same vendor runtime service:
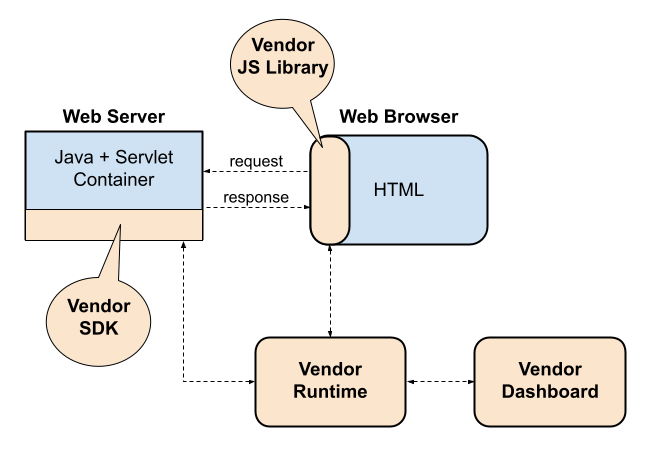
Abe Lincoln is rumored to have remarked that you can’t fool all of the people all of the time. That this architecture can’t work eventually became apparent not just to some, but to all. Here’s just the most glaring problems:
- The need for server-to-server communication makes the host application’s backend geographically distributed with potentially multiple calls across unreliable internet per single user request. The network latency and spurious failures are just too great to be reasonably tolerated. Network problems can always be mitigated with caching in CDN and in SDK, but that requires experiment metadata to be essentially static, which dramatically reduces the range of serviceable use cases.
- The SaaS architecture no longer applies. The division of labor between the client code running in the host application’s backend, and the vendor runtime becomes moot. Most server-side experiments require more than just the ability to inquire from the vendor runtime what experience to serve. The proximity to the operational data makes it feasible for the host application to implement its own targeting based on real time operational data, but that would flip the chain of responsibility. It is also not clear what side is collecting the logs for the downstream statistical analysis. If vendor is still to be relied on for the statistical analysis, it needs the logs it can’t produce. If the customer to take over the analysis, it is not clear why vendor is even in the picture.
- The fast bloat of the instrumentation code inside the host application leads to instrumentation code smell, a condition where application domain is littered with brittle and bug-prone unrelated experiment-instrumentation. Which would be workable for an occasional ad-hoc A/B test, but at even moderate scale of testing would need to be factored out into a server-side experimentation infrastructure—the very thing the customer set out to avoid in the first place.
In summary, the fundamental flaw of all existing commercial A/B tools is that they all started out as SaaS, which was a reasonable approach to the shallow experiments—their beachhead market,—but that architecture proved untenable when they attempted to extend down the host application’s stack. Without cogent support for full-stack experiments enterprise customers by enlarge opted to roll their own. In the subsequent installments, as I cover typical use cases, it will become absolutely clear that the architecture in Figure 4 just can’t support them.
Comments are closed.